Most South African brands are still treating AI search as a new flavour of SEO. They are running the same playbook, generating the same content, deploying the same schema, and waiting to see where they end up in ChatGPT and Perplexity answers. This is a category mistake. It costs ranking, it costs visibility, and it costs deals to competitors who have figured out the difference.
The reason is structural. For two decades, the major search engines converged on shared infrastructure. Sitemaps became a joint property of Google, Yahoo and Microsoft in 2006. Schema.org launched as a Google, Bing and Yahoo collaboration in 2011. robots.txt was formalised as an IETF standard in 2022. If you optimised for one search engine, you were largely optimising for the others. The plumbing was shared.
AI search has no shared rulebook
AI search does not work that way. Each engine runs a different retrieval architecture, licenses different training data, and applies a different alignment methodology to decide what to cite. Perplexity built its own Vespa pipeline. ChatGPT still leans on Bing's index. Claude pairs with Brave Search. Gemini uses Google's own index plus the Knowledge Graph. The shared sitemap protocol never arrived. The shared structured-data standard for AI never arrived.
The proposed llms.txt file (the closest thing the industry tried to a shared rule) is not consumed by any major AI engine. Google's Gary Illyes confirmed at Search Central Live in July 2025 that Google does not support it and is not planning to. John Mueller compared it to the deprecated meta keywords tag.
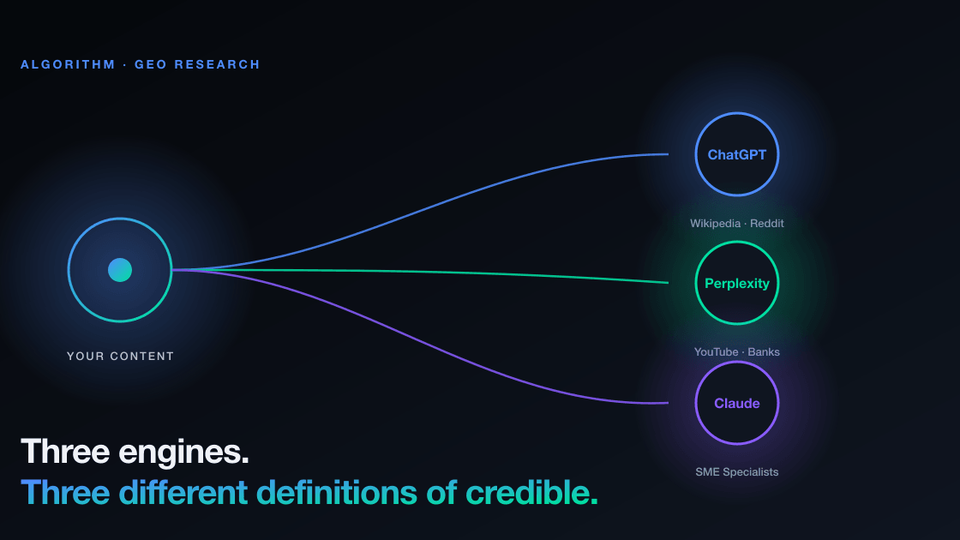
The result: there is no single AI search channel. There are at least four very different ones, each with its own definition of credibility and its own list of sources it trusts.
We measured this in South Africa
We tested the thesis in our own market. Algorithm Lighthouse, our proprietary AI visibility platform, ran 2,737 prompts across ChatGPT, Perplexity and Claude across 43 South African brands. We captured every citation each engine returned. 46,315 in total.
“83.4% of the cited domains appeared on only one platform.
Read that again. More than four out of every five sources that AI engines cite about South African brands are not cited by the other engines for the same question. The shared sources that anchored SEO (high-authority directories, dominant publishers, Wikipedia-style references) only weakly anchor AI search. Each engine has its own list, and the lists do not overlap.
The full per-engine data, sector breakdown and methodology sit in the companion piece: We measured 46,315 AI citations in South Africa. This piece is about what changes in the SEO playbook because of that finding.
Five SEO moves that do not transfer to AI search
None of these were wrong for Google. They are wrong for AI search because the underlying premise (a shared rulebook) does not hold. Each one needs to be replaced with a per-engine equivalent.
01. Optimising for AI search as one channel
There is no AI search. There are ChatGPT, Perplexity, Claude, Gemini and four more, each running a different retrieval architecture and a different definition of credibility. Treating them as one audience produces work that fits none of them.
02. Chasing rankings as a proxy for visibility
Between 60 and 76% of each engine's cited South African sources do not appear in the other engines' cited sources at all. A page that wins position one in Google can still be invisible across all three AI engines we measured. Ranking is no longer a proxy for AI visibility. You have to measure AI visibility directly.
03. Producing more content to hedge across platforms
Volume does not buy uniform coverage. Perplexity already cites 12.5% more sources per response than ChatGPT in South Africa, and the marginal cited domain is platform-specific 83 times out of 100. More content does not solve the fragmentation problem. Better-targeted content does.
04. Treating Wikipedia and Reddit as edge-case sources
For ChatGPT in South Africa, Wikipedia and Reddit are the top two cited domains. They beat every local source. If your topic does not exist on Wikipedia, or your category has no signal on Reddit, you have a structural ChatGPT visibility problem before you write a word of your own content.
05. Building one schema stack and assuming all engines read it the same way
Each engine privileges different signals. Claude favours niche specialist domains. Perplexity favours video and established institutional brands. ChatGPT favours encyclopedic and community sources. Schema, structured data and content design need to map to those preferences, not to a generic AI-ready checklist.
What to do instead
The work that follows from this is per-engine, not aggregate. Measure each engine separately. Map which third-party domains each one cites in your category. Audit your Wikipedia and Reddit footprint for ChatGPT. Diversify content format for Perplexity. Build authority on niche specialist publications for Claude. Monitor weekly via API, not quarterly via scraping.
This is the work we run for Lighthouse clients every week. The full per-engine maps, sector breakdowns and 90-day action plan are in our companion research piece: We measured 46,315 AI citations in South Africa.
Get the data for your category
Algorithm runs a free Lighthouse visibility audit for South African brands. Same methodology as the research. You see exactly which domains each engine cites about your category and where your brand appears (or does not). Real data from your category, not a template. Get in touch to book one.


